自己写python爬虫框架(四)-请求管理器
前言
请求管理器是对所有的 请求 进行管理,保证爬取过的 请求 不再重复被爬取,未被爬取的 请求 按照一定的优先策略进行爬取。在请求管理器中需要具体实现我们对于请求的排队策略。排队策略则是在操作系统常见的有:先进先出、短作业优先、多级队列、轮转调度、多级反馈队列等等。而在请求管理器中还需要注意我们是对网络数据的抓取,在网络中访时问,是选择广度优先的策略还是深度优先呢?
在本爬虫通用的请求管理器中选用广度优先的策略,当同一广度的 请求 都被访问之后接着对下一深度的 请求 进行访问,每个深度设置一个队列按照先进先出的排队策略,同时维护一个已爬取 请求 池,对所有新添加的 请求 进行判断,是否已经爬取过,倘若已经对该 请求 进行爬取,便不再重复爬取。对于深度使用 level 标识,初始深度为 1,依次递增。初始化请求管理器的时候会初始化一个最大深度限制变量 limit_level,防止爬虫陷入网络死循环,值默认为 1,可在初始化请求管理器的时候自定义值。
请求管理器实现
可以来看看请求管理器的抽象结构,主要有三个方法:添加请求、判断是否还有新请求、取出请求
1 | def add_new_request(self, request): |
因此,请求管理器最简单的实现便是维护一个队列,在队尾添加新的请求,队首 pop 请求,当队尾指针与队首指针指向同一数据时,则表示队列为空,没有请求了。
本爬虫按照广度优先的策略,维护一个多级队列,分别存储管理不同网络深度的请求。每一级别的队列按照先进先出的排队策略。需要维护一个已爬取请求池,判断且保证对于所有爬取过的请求不能二次爬取。并且初始化一个最大深度限制爬取深度。这样看来请求管理器在初始化时需要维护一个多级队列、一个已爬取请求池以及一个最大深度变量:
1 | def __init__(self, limit_level=1): |
接下来我们需要实现具体的添加请求、取出请求的细节。
添加请求是将外部传入的请求添加到请求管理器中,但是请求可能是已经被访问过的,所以我们需要扔进已爬取请求池中判断:是否被访问过,如果已被访问过,那便不再添加到请求管理器中;反之,将其添加到请求管理器中。因此,我们的实现逻辑为:
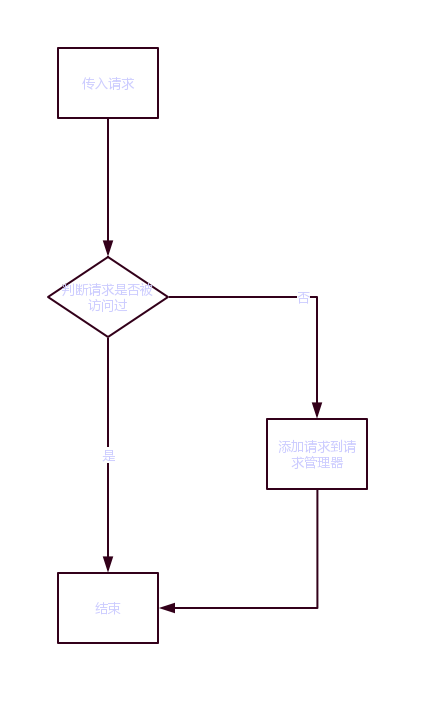
在具体的实现中,我们将新的请求添加到请求队列的同时,还将请求添加到了已爬取请求池中,这样可以防止在我们还未进行访问该请求却已经添加该请求到请求队列的这一段时间中插入重复已有的请求。
1 | @typeassert(request=Request) |
请求队列是多级队列,所以在添加请求的时候还需要根据请求的深度去初始化队列并添加请求。具体做法如下:
- 如果请求深度大于请求管理器最大爬取深度,则直接返回
- 如果当前多级队列容器不存在这一层级,则初始化这一层级的队列
- 添加请求到相应层级的队列中
1 | def __add_new_request(self, request): |
将请求添加到了已爬取请求池的实现中,考虑到存储已爬取请求信息只是为了验证该请求不被重复爬取,所以我们选择了 MD5 算法将请求信息转换为 128 位的摘要,这儿只取 32 字节的摘要进行判断,大大的节省了内存的消耗
1 | def __add_old_request(self, request): |
将请求添加到请求管理器中,我们还需要将请求取出来使用。请求的取出可以按照队列的级别取出相应队首的请求,也可以直接取出此时请求管理器中最优先的请求:
1 | def get_new_request(self, level=self.__level): |
同样的,判断请求管理器中是否还有未被访问的请求与取出请求类似:
1 | def has_new_request(self, level=None): |
可扩展思考
以图的结构存储 请求(通过邻接表数据结构或者图数据库),这样便可参数化的选择广度优先策略或是深度优先策略了。
如何扩展到分布式呢
本文作者 : 对六
原文链接 : http://duiliuliu.github.io/2019/04/16/自己写python爬虫框架四/
版权声明 : 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
你我共勉!

