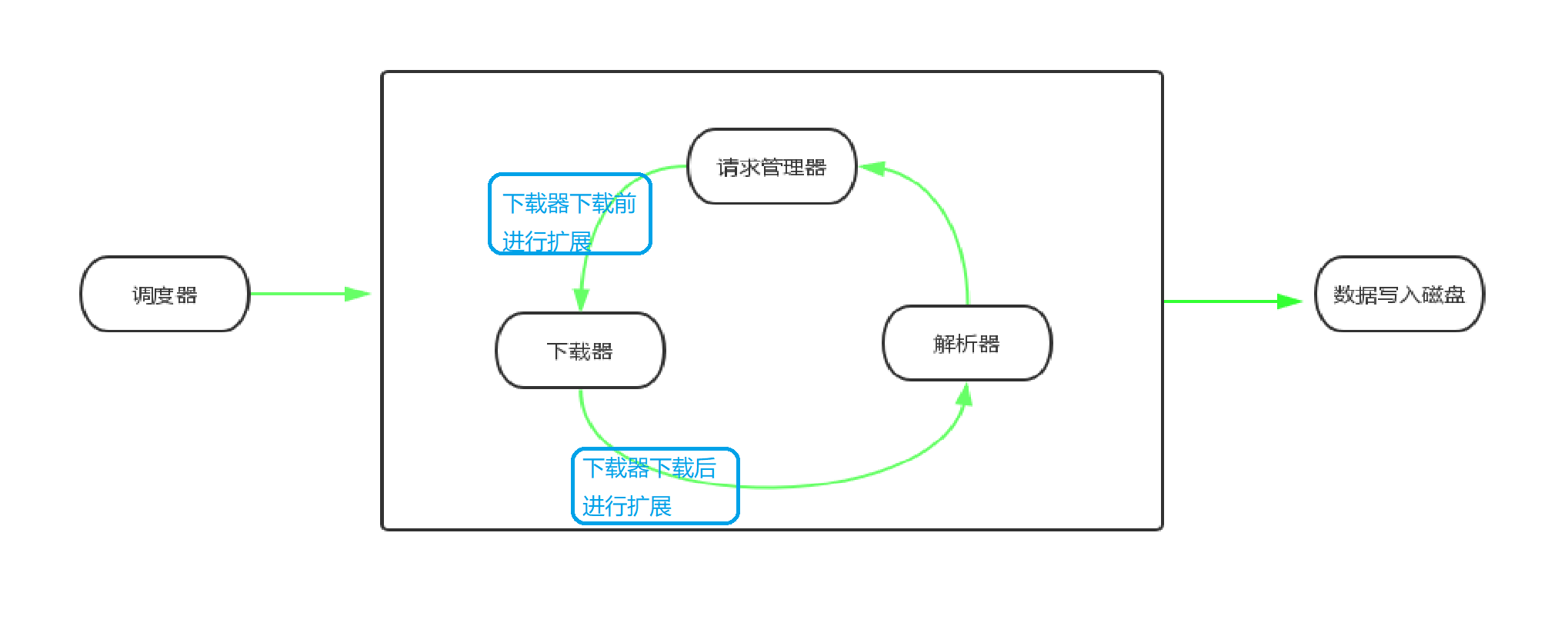
前言 下载器,顾名思义是对数据资源进行下载,python 中自有 urllib 网络库可对网络资源进行请求下载。不过在 python 生态中有个 requests 网络库是对 urllib3 对封装,提供了简单易用的 api,我们的爬虫下载器则是选用该框架进行实现。
request 文档
基本的功能则是根据传入的 url 及请求方法、请求数据便可以进行网络请求。
在 web 网络交互中,很多网站后台服务器会存储用户信息保持会话,以及使用用户信息生成的 token 进行页面验证,并且很多网站对与爬虫是有防备策略的,这个时候爬虫就需要进行伪装 ip 地址、伪装身份进行爬取数据。这样一来,对于网络请求中构建的请求对象便需要很多属性了,例如:代理 IP、web 交互中需要的 cookie、useragent、ssl 证书验证等等。不过 requests 网络库强大的支持这些需求,免去了我们很多工作。
下载器实现 下载器实现:传入一个 reqeust 对象,返回网络请求到的 response
这样来看,我们需要封装一个 request 对象与 response 对象
request 对象是请求对象,其属性也就是 web 网络请求中存在的属性,以及额外的属性代理 ip、请求权重等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 class Request(object): ''' 请求对象 @member :: method : 请求方法,有GET、POST、PUT、DELETE、OPTION @member :: url : 请求url @member :: params : 请求参数 @member :: data : 请求body数据 @member :: headers : 请求headers @member :: cookies : cookies @member :: files : files @member :: auth : auth @member :: timeout : timeout @member :: allow_redirects : allow_redirects @member :: proxies : 代理,为字典结构,{'http':'10.10.154.23:10002','https':'10.10.154.23:10004'} @member :: hooks : hooks @member :: stream : stream @member :: verify : verify @member :: cert : cert @member :: json : json @member :: level : level ''' __attrs__ = [ 'method', 'url', 'params', 'data', 'headers', 'cookies', 'files', 'auth', 'timeout', 'allow_redirects', 'proxies', 'hooks', 'stream', 'verify', 'cert', 'json', 'level' ] def __init__(self, method, url, params=None, data=None, headers=None, cookies=None, files=None, auth=None, timeout=None, allow_redirects=True, proxies=None, hooks=None, stream=None, verify=None, cert=None, json=None, level=1): self.method = method self.url = url self.params = params self.data = data self.headers = headers self.cookies = cookies self.files = files self.auth = auth self.timeout = timeout self.allow_redirects = allow_redirects self.proxies = proxies self.hooks = hooks self.stream = stream self.verify = verify self.cert = cert self.json = json self.level = level
response 为响应对象,是对网站后台响应数据的包装。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 class Response(ParentResponse): ''' 响应对象 @member :: _content : 响应二进制数据 @member :: _content_consumed : _content_consumed @member :: _next : _next @member :: status_code : 响应状态码 @member :: headers : 响应头 @member :: raw : raw @member :: url : 请求url @member :: encoding : 响应编码 @member :: history : 响应历史 @member :: reason : reason @member :: cookies : 响应cookies @member :: elapsed : elapsed @member :: request : request @member :: level : 对应request的level ''' def __init__(self, level, cls=None, **kwargs): if cls: self._content = cls._content self._content_consumed = cls._content_consumed self._next = cls._next self.status_code = cls.status_code self.headers = cls.headers self.raw = cls.raw self.url = cls.url self.encoding = cls.encoding self.history = cls.history self.reason = cls.reason self.cookies = cls.cookies self.elapsed = cls.elapsed self.request = cls.request else: super().__init__(**kwargs) self.level = level def __getitem__(self, item): return getattr(self, item) def html(self, encoding=None, **kwargs): if not self.encoding and self.content and len(self.content) > 3: if encoding is not None: try: return html.fromstring( self.content.decode(encoding), **kwargs ) except UnicodeDecodeError: pass return html.fromstring(self.text, **kwargs)
有了封装好的 Request 类与 Response 类,便可以传入 Request 类进行网络请求下载,将网络响应数据包装为 Response 返回,其中网络请求使用 requests 网络库实现
1 2 3 4 5 6 7 8 9 10 11 12 class HtmlDownloader(AbstractDownloader): ''' 下载器 对传入的请求进行请求下载 ''' @typeassert(request=Request) def download(self, request): with sessions.Session() as session: return Response(request.level, cls=session.request(**request.TransRequestParam()))
具体实现的下载器继承(实现)之前定义好的下载器接口,@typeassert 对传入的参数类型进行校验,传入参数 request 必须为 Request 类,运用将 requests 库请求到的数据包装为 Response 返回
可扩展思考 对与下载器下载前后,很多时候都需要进行一些扩展中间件,在此框架中,可以运用装饰者模式对其进行扩展,也可以自己继承实现 AbstractDownloader 接口中的方法。
例如:通过装饰器实现添加代理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ## 我们需要一个代理池(可将代理池设置为单例类),类似与requestManager.假定我们得代理池如下: class ProxyPool(object): def get_new_proxy: ''' 请求代理,返回一个可用的、未被使用过的代理 return proxy ''' pass def proxyWrapper(): ''' 通过装饰器给请求动态添加代理 ''' def decorate(func): @wraps(func) def wrapper(request): proxy = ProxyPool().get_new_proxy() request.proxy = proxy return func(*args, **kwargs) return wrapper return decorate
完成代理的装饰器后可直接在 download 方法中进行使用:
1 2 3 4 5 @typeassert(request=Request) @proxyWrapper def download(self, request): with sessions.Session() as session: return Response(request.level, cls=session.request(**request.TransRequestParam()))
同样的,我们可以用类似的方法在下载的时候给请求动态添加 user-agent、cookie 等