自己写python爬虫框架(一)
前言
作为一个爬虫框架,与其他爬虫相比:灵活易扩展以及入门简单
整体架构
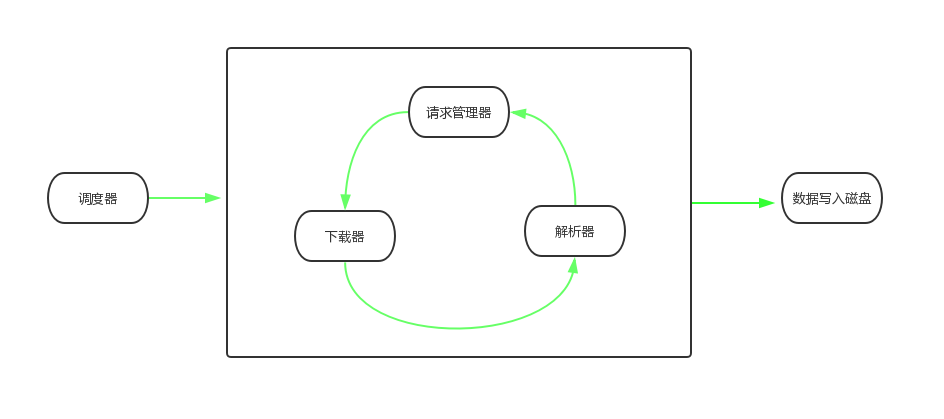
对该爬虫设计架构中有以下 5 个关键组件:
调度器
从请求管理器中取请求,然后调用下载器进行下载,调度解析器进行解析,对解析出的请求再次加入到请求管理器中;解析出的数据进行缓存,最后写入到文本中调度器为爬虫框架的核心,也是爬虫的入口,其成员变量为下载器、解析器、请求管理器、文件写入类、日志类,对于不同的爬虫需求,可以对以上接口有不同的实现。
核心方法:
从请求管理器中取用 request,采用模板设计模式,不可被子类重写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def run(self, request):
'''
运行爬虫方法,从requestManager中取出可用的request,然后扔进下载器中进行下载,通过解析器对下载到的文档进行解析;
需要传入一个或者一组request作为初始request进行抓取
@param :: request : Request类型请求
return : None
'''
self.__start_icon()
self.__logger.info('\tStart crawl...')
self.__requestManager.add_new_request(request)
while self.__requestManager.has_new_request():
request = self.__requestManager.get_new_request()
print(request.__dict__)
self.crawl(request)
self.__logger.info('\tEnd crawl...')调度下载器与解析器,可被子类继承扩展,可扩展为多线程、多进程等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20def crawl(self, request):
'''
对request进行请求进行爬取并解析结果的运行单元,子类可对该方法重写进行多线程、多进程运行或异步抓取与解析;也可装饰该方法,进行多线程、多进程抓取。
下载器对传入的request进行下载,解析器解析下载到的文档,并将解析出的request扔进requestManager中进行管理,以进行深度爬取;将解析出的data扔进writter中,将数据存储到磁盘上
@param :: request : Request类型请求
return None
'''
try:
self.__logger.info('\t'+request.url)
response = self.__downloader.download(request)
if response.status_code == 200:
requests, data = self.__parser.parse(response)
self.__requestManager.add_new_requests(requests)
self.__writter.write_buffer(data)
else:
self.__logger.warn(
'crawled data is None and response_status is ' + str(response.status_code))
except Exception as e:
self.__logger.exception('\tCrawling occurs error\n' + e.__repr__())下载器
对传入的请求进行请求下载抽象方法:
1
2
3
4
5
6
7
8
9def download(self, request):
'''
对request进行请求下载,需要将请求到的response返回
@param :: request : 请求对象
return response
'''
raise NotImplementedError("未实现的父类方法: %s.%s" % (
self.__class__.__name__, get__function_name()))解析器
对传入的文本进行解析抽象方法:
1
2
3
4
5
6
7
8
9def parse(self, response):
'''
对response进行解析,需要将解析到的requests与data返回
@param :: response : 响应对象
return requests,data
'''
raise NotImplementedError("未实现的父类方法: %s.%s" % (
self.__class__.__name__, get__function_name()))请求管理器
管理所有的请求抽象方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38def add_new_requests(self, requests):
'''
模板方法,不需要子类重写
添加requests序列到requestManager中进行管理
@param :: requests : request对象列表
return None
'''
for request in requests:
self.add_new_request(request)
def add_new_request(self, request):
'''
添加request对象到requestManager中进行管理
@param :: request : request对象
return None
'''
raise NotImplementedError("未实现的父类方法: %s.%s" % (
self.__class__.__name__, get__function_name()))
def has_new_request(self):
'''
判断requestManager中是否还有新的请求,返回布尔类型结果
return Bool
'''
raise NotImplementedError("未实现的父类方法: %s.%s" % (
self.__class__.__name__, get__function_name()))
def get_new_request(self):
'''
从requestManager中取新的请求
return request
'''
raise NotImplementedError("未实现的父类方法: %s.%s" % (
self.__class__.__name__, get__function_name()))数据写入类
将数据以特定格式写入到磁盘中抽象方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26def write(self, data):
'''
将数据data写入磁盘
return None
'''
raise NotImplementedError("未实现的父类方法: %s.%s" % (
self.__class__.__name__, get__function_name()))
def write_buffer(self, data):
'''
缓存数据
return None
'''
raise NotImplementedError("未实现的父类方法: %s.%s" % (
self.__class__.__name__, get__function_name()))
def write_buffer_flush(self, data):
'''
刷新缓存数据到磁盘上
return None
'''
raise NotImplementedError("未实现的父类方法: %s.%s" % (
self.__class__.__name__, get__function_name()))日志
记录爬虫运行抽象方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34def debug(self, message):
'''
debug级别日志
'''
raise NotImplementedError("未实现的父类方法: %s.%s" % (
self.__class__.__name__, get__function_name()))
def info(self, message):
'''
info级别日志
'''
raise NotImplementedError("未实现的父类方法: %s.%s" % (
self.__class__.__name__, get__function_name()))
def warn(self, message):
'''
warn级别日志
'''
raise NotImplementedError("未实现的父类方法: %s.%s" % (
self.__class__.__name__, get__function_name()))
def exception(self, message):
'''
exception级别日志
'''
raise NotImplementedError("未实现的父类方法: %s.%s" % (
self.__class__.__name__, get__function_name()))
def error(self, message):
'''
error级别日志
'''
raise NotImplementedError("未实现的父类方法: %s.%s" % (
self.__class__.__name__, get__function_name()))
设计思想
抽象工厂模式为将’抽象零件’组装为’抽象产品’,该模块运用抽象工厂模式。对于下载器、解析器、请求管理器、数据写入类、日志类仅是限定其抽象接口,在调度器中分别调用其每个零件的具体实现。
调度器则参照了模板方法设计模式,将开始爬取方法(startcrawl)固定,对于调度器的多线程多进程扩展可继承该调度器,并重写调度爬取方法(crawl),提供多线程多进程爬取方法
在爬虫整体框架设计中,主体未调度器、下载器、解析器、请求管理器、数据写入类、日志类,满足了基本爬虫的需求,在实际中爬虫进行爬取数据时,需要设置网络代理、设置不同的 cookie 身份、以及分布式爬取调度任务等,可对以上基本组件运用装饰者模式进行装饰,已达到扩展功能的需求
多线程、多进程、异步的扩展:
- 以一次调度为单位,继承调度器,将每次调度作为一个任务添加到线程池、进程池中
- 以一次下载为单位,继承下载器,将每次下载作为一个任务添加到线程池、进程池中,解析器从线程池、进程池中取运行结果,达到异步的效果
- 类比以上想法中,将解析作为任务单位添加进线程池、进程池
相关设计模式:
Abstract Factory 模式
Template Method 模式
本文作者 : 对六
原文链接 : http://duiliuliu.github.io/2019/04/10/自己写python爬虫框架一/
版权声明 : 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
你我共勉!

